
全世界共有超過 6000 種語言,科技巨頭們正在嘗試用新技術彌合人與人之間的溝通障礙。但是,相信任何有用過Google翻譯或是其它機器翻譯工具的使用者,都會告訴你這樣的答案:機器翻譯的體驗實在是太糟糕了,根本無法直接拿來使用。
前兩個月,微軟旗下的 Skype 推出了一項“即時翻譯”的功能,英語和西班牙語的用戶交流時,Skype 會自動翻譯,並語音播送。
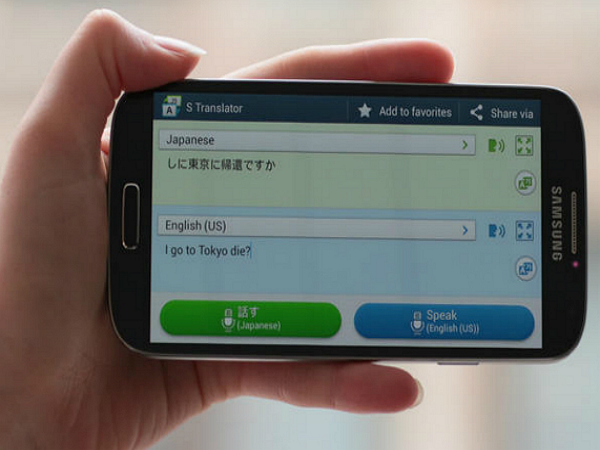
如今,類似的功能也成為 Google 要攻下的城池:Google Translate 將增加支援語種達 90 種,同時針對個別語言支援「語音翻譯」——用語音輸入 A 語言,應用翻譯出 B 語言的文字。
但是,不管是Skype或是Google,通常他們的翻譯結果都不會如你所願。
即便是純文字版的 Google Translate 也常常伴生著語法、語序的錯誤。Skype 的即時翻譯同樣如此,從宣傳片的使用演示中看,這項功能要配合耳機,整個過程仿佛是兩個接線員在用對講機。

包括 Google Translate 的機器翻譯,這些翻譯的侷限在於機器演算法和語言文學性的差異。機器翻譯無法提供準確的譯文,它經常忽略語境、上下文來翻譯詞彙,也並不遵守語法。機器翻譯,現在仍然處在「詞典」的階段。
Google翻譯的演算法基於統計分析,重在翻譯效率而非準確性。但是,人類語言本身具有「人性」,包括語法、語義、情感,這些都無法被演算法翻譯。
儘管如此,人們還是迫切的需要翻譯應用。Google Translate 的下載量已經超過 1 億,月活躍用戶達到 5 億。機器翻譯的背後是一個巨大的市場。包括 Facebook、微軟在內的巨頭都進行著翻譯機器的計畫。
可以預見,未來的機器翻譯,會在準確性上大大提升,這就依靠一個龐大的資料庫,使用的人越多,使機器不斷學習,讓機器更加理解人。
在形式上,未來的翻譯也將更為智慧化,比如即時翻譯,類似現在的人工同步傳譯。Skype 的即時翻譯雖然在效率上有待提高,但是卻提供了一個奇妙的前景,機器翻譯的最終使命,就是消除語種的差異。
以資料和演算法方式做翻譯可以讓翻譯系統會隨著資料的積累而不斷地學習改進,但是這裡又產生了一個新的問題:如果資料庫積累使用者的語言內容和習慣,勢必涉及使用者的個人隱私。語言研究機構 Hypervoice Consortium 表示,僅僅有 1% 的使用者願意貢獻自己的使用資料,來讓翻譯機器學習。而大多數的使用者則希望,翻譯機器就像 Siri 一樣,將資料封閉,只為自己服務。
為了促進機器翻譯的人性化,你願意把你的日常對話變成公共資料嗎?這恐怕會是未來網路上新的議題。
![]()

字詞記錄簿其實用起來不錯
累積龐大一點的話
翻譯的準確率會變高
用自已的語言和外國人交談
借由這個方式來調校翻譯品質
這應該是大家都樂見的 (≧▽≦)
google的演算法不會忽略喔,只是現在數據庫不夠大不夠精準,以前google翻譯的數據庫成長了錯誤率應該會變小
> > 它經常忽略上下文來翻譯詞彙
> google的演算法不會忽略喔,只是現在數據庫不夠大不夠精準,以前google翻譯的數據庫成長了錯誤率應該會變小
你要說以後吧