

ADVERTISEMENT
自從2006年 AMD 收購 ATi 之後,Fusion 異構核心的概念不絕於耳,AMD 和 Intel 雙方也都推出融合處理器與顯示核心的產品,不過這類內建顯示核心的處理器一直都有個很現實的問題,就是無法提供足夠的效能來取代獨立顯示卡,即使在玩遊戲的時候就算把畫面特效調低,也不見得能夠流暢地執行。就讓我們來看看,第二代APU的架構與效能,是否能夠滿足大家對內建顯示的期望。
三位一體處理器
第二代APU的代號為Trinity,這個字原為基督教神學術語「三位一體」,三位一體論主張聖父、聖子、聖靈為同一本體,三者皆為神的樣貌,但是聖父、聖子、聖靈並不等同於彼此。
AMD則是借用這個典故,將打樁機(Piledriver)架構的處理器,北方群島(Northern Islands)VLIW 4架構的顯示核心,以及南方群島(Southern Islands)架構的影像引擎與Eyefinity模組,三者合併,成為APU的特色,但是卻又是不同的技術,總之就是讓能夠一次滿足消費者3個願望的混合處理器。
下一台工程車是打樁機
Trinity的處理器部分採用打樁機架構,除了與先前的推土機(Bulldozer)架構都是以工程車輛命名外,彼此的架構也頗為類似,兩者都是在1個雙核心模組內,塞入2個整數運算單元以及2組L1快取記憶體,整個雙核心模組,卻分享共同的預取器、解碼器、浮點運算單元,以及L2快取記憶體。然而Trinity與推土機架構的FX系列處理器最大的不同,在於缺乏L3快取記憶體。
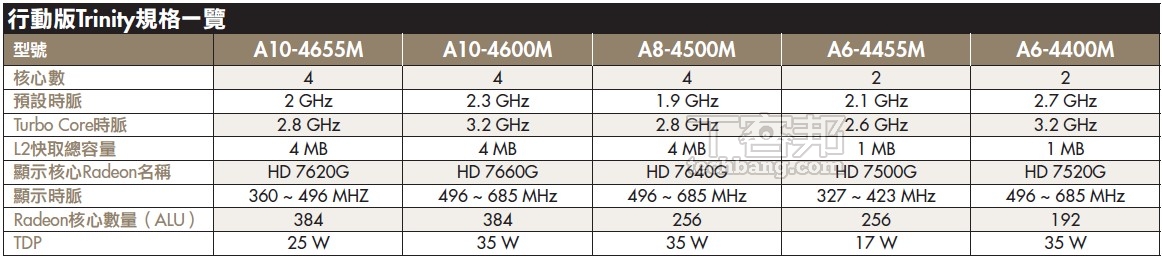
(點圖可看大圖)
為了增進處理器效能,Trinity改善了分支預測的架構,以2階預測方式增進整體分支預測的效能。它會將過去預測的記錄及分支模式存在暫存器中,並藉此提高分支預測的「學習」速度,除此之外,擴大的指令窗口也有助於處理更龐大的指令群組,其指令解瑪器寬度為4-wide,在單核心及雙核心模式(使用單一雙核心模組)下可以同時處理最多4條指令,在4核心模式(使用2個雙核心模組)下則可同時處理最多8條指令。在快取方面,為了要降低存取時的延遲,L1快取記憶體的轉譯後備緩衝區(Translation Lookaside Buffer,TLB)的通道增加至64個,為前代產品的2倍,同時也為L2快取記憶體增加硬體預讀器。
製程不變時脈飆升
不同於Intel在Sandy Bridge過渡Ivy Bridge時,將製程從32nm進化為22nm,Trinity與上代APU Llano的製程相同,皆為32nm,不過電晶體總數從11.78億成長為13.03億,因此核心面積(die size)尺寸從228 m㎡長大為246 m㎡,成長幅度約為7.89%。
至於另一個增進效能的老哏,你我都想得到,那就是加快處理器運作的時脈。A10-4655M的Turbo Core時脈高達3.2GHz,與上代TDP相同的A8-3500M相比,其Turbo Core時脈僅有2.5 GHz,前後代產品時脈的成長達28%,其幅度之大不容小覷。
CPU、GPU都會自動超頻
上一代APU會在處理器尚未到達TDP極限時,依負載動態調整時脈,以達到省電與效能並進的目的,然而顯示核心則不具此功能。AMD在Trinity導入第3代Turbo Core 3.0,它除了具有處理器自動超頻功能外,在整體TDP還有餘裕的情況下,也能依負載調整顯示核心的時脈。
Turbo Core 3.0的超頻功能是雙向的,它並不是單純線性式地同時提高雙方的運作時脈,而是協調處理器與顯示核心,彼此分享可用的資源(電力以及TDP)。在只有運算或顯示之一的效能需求較高時,Turbo Core 3.0可以只提高單一部分的時脈,讓時脈有機會達到最高值,當運算與顯示的需求同時存在時,Turbo Core 3.0就會同時提高兩者的時脈,但時脈可能會因TDP達到上限而略低於最高值。
整合式北橋為GPU鋪路
Trinity為首次導入了整合式北橋(Unified Northbridge,UNB)的APU,UNB掌管了許記憶體控制,以及聯絡外部裝置等重要功能,並以PCI-E介面取代Hyper Transport匯流排,成為處理器對外部裝置聯絡的唯一媒介。

▲Trinity的功能區塊示意圖。DDR3、PCI-E x16以及影像輸出等控制器都內建於處理器中,其餘速度較慢的裝置功能則是放在外部晶片組。
▲Trinity的die shot。左側處理器部分包括2個雙核心模組,右側是佔用將近一半面積的顯示核心,上下則是記憶體、PCI-E、影像等各種連外通道。
為了要滿足顯示核心與處理器、記憶體溝通的需求,UNB中設有2條特殊的通道。顯示核心可以透過Fusion Control Link與處理器溝通,並存取處理器中的快取記憶體,其頻寬為單向128 bit。另一條通道是Readon Memory Bus,它為顯示核心提供單向256 bit頻寬與記憶體通道控制器連絡,若系統記憶體運作於雙通道模式的話,顯示核心總共可以獲得單向512 bit(雙向總計1024 bit)的資料傳輸頻寬。
(後面還有更多介紹喔!)
延伸閱讀:
看懂 AMD Trinity 新平台:進軍筆電市場,CPU、GPU 一起來加速
AMD、Intel 處理器混戰,Trinity、Piledriver、Ivy Bridge 近期現身

難道Llano不是UNB架構?
不過省電會比Intel的好嗎?!
反正現在顯卡TDP都高過CPU,乾脆AMD出顯卡,晶片附送CPU吧,如同tegra3一般,低耗能的交給顯卡上的cpu,高需求轉給原CPU,或再協同也可以.
現在I7幾乎沒進步
E3還能被超頻的第一代I7穩穩幹掉
坦白說X86跑分越來越沒有討論價值了