
ADVERTISEMENT
Kepler:2倍速的運算架構
先前提到,受到新製程的影響,Kepler核心能塞下更多的硬體單元,並且電力效率能表現更好。雖說大多數的設計與Fermi差異不大,但是我們還是來看看Kepler跟Fermi的幾個關鍵架構如何運作。
PolyMorph Engine
PolyMorph Engine也就是多形體引擎,是NVIDIA在Fermi架構中新增的硬體單元。在Kepler架構中,PolyMorph Engine雖然進化到2.0版本,但是數量、作用、架構都與先前無異,而在效率方面,官方數據指出將會有2倍的效能。筆者認為這跟GF 100、GF 110的情況相似,更改或修正的部分是較為底層的設計,也就是當時官方所謂「電晶體層面的修正」,因此會有效能上的提升,而無架構方面的改變。
PolyMorph Engine的作用是什麼?它包含Vertex Fetch(頂點預取)、Tessellator(Tessellation產生器)、Viewport Transform(視口轉換)、Attribute Setup(屬性建立)與Stream Output(數據流輸出)共5個階段。
 (點圖可放大)
(點圖可放大)
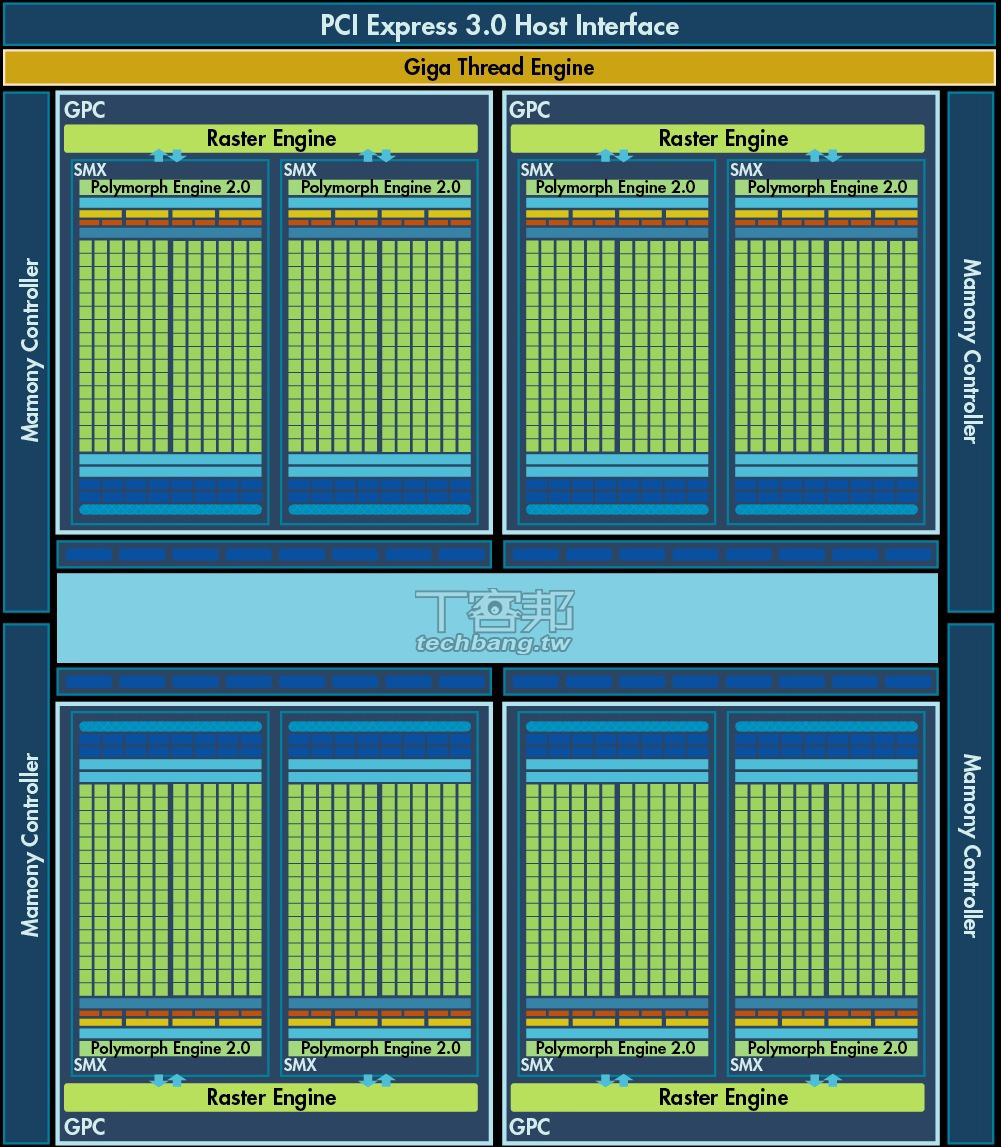
▲Kepler與Fermi架構相當相似,最大的差異在於SMX架構大幅擴增,且支援PCI-E 3.0控制器。至於在SMX內,像是PolyMorph Engine升級到2.0版,不過就算是官方也只有表示電力效率有所提升。筆者認為,Kepler的價值反而是GPU Boost、Adaptive VSync等新功能,比起效能更值得期待。
5個運算階段
PolyMorph Engine的運作首先從緩衝區預取頂點,在SM內進行頂點跟像素運算,並在這個階段計算Tessellation的參數。接著第二步是透過Tessellator輸出新的頂點,而先前提到的Tessellation參數就是用於確認Tessellation的強度,強度越高頂點越多,所形成的圖形表面也就越逼真。
第二步中的頂點確認後會傳送給Domain Shader(區域著色引擎,簡稱DS)跟Geometry Shader(幾何著色引擎,簡稱GS)進行運算。DS將根據Hull Shader(外殼著色引擎,簡稱HS)加上Tessellator給予的數據,生成最終的3D模組頂點。這個階段完成後,通常還會透過Displacement Mapping(位移貼圖),讓Tessellation生成的圖形表面不會只有平面與稜角,白話來說就是更有立體感跟凹凸感。
再來第三步就是Viewport Transform字面上的視口轉換以及視角校正,完成後則是Attribute Setup,會將這些頂點屬性轉換為方程式,最後Stream Output則是將這些數據傳送到記憶體內,接著讓Raster Engine來處理。

▲PolyMorph Engine包括5個運算階段,每個階段完畢都會由SM內的單元進行運算,完畢後再傳回PolyMorph Engine,所有階段都完畢後,轉給Raster Engine處理下一步。
關鍵字:Tessellation
Tessellation原意是鑲嵌,大多翻譯為細分曲面(subdivision surface)、平面填充或密鋪。在支援DirectX 11的顯卡上,因為Tessellator而具備「無中生有」的能力,可讓原本的3D模組產生更多三角形。用白話來說就是一種讓多邊形細分為碎片的方法,藉此獲得更細緻的物體表面。
以往的3D模組,若使用大量多邊形,會增加程式設計的時間,並消耗顯卡效能;若使用的多邊形數量不夠,又會讓模組看起來稜稜角角,感覺會假假的。透過Tessellation技術,GPU能自行生成更多的三角形來填滿原先的框架,就像讓原先的模組貼了細緻的表皮。
▲以圖中的海浪為例,設計時只要先做出果凍般的框架,使用時只要開啟Tessellation,GPU就會自行生成多邊形,讓海洋的浪濤跟陰影顯現出來。不過光只有Tessellation仍不足夠,再配合Displacement Mapping效果會更好。
Raster Engine
由於PolyMorph Engine的加入,尤其是距離3D模組十分近的時候,Tessellator無中生有了許多三角形。為了避免Raster成為效能上的瓶頸,於是每個GPC都內建1組Raster Engine,且這4組Raster Engine可平行運算,能提高運算效率。那麼Raster Engine的工作到底是什麼?用最簡單的話來說,就是「把3D世界變成2D影像」,更直觀地來說就像是拍照。不過Kepler的Raster Engine數量並沒有增加,會不會造成運算上的瓶頸?還要經過測試才知道。
Tips:3D與透視技法
Raster Engine的工作是透過方程式,將3D頂點座標變換成2D頂點座標,成為沒有Z軸的影像。這過程類似西方寫實派繪畫的透視技法,讓你即使在2D螢幕前面,也能保有有3D的立體感。不過Raster Engine處理的這個過程更具破壞性,有些人會將這個3D轉2D這過程賦予另外一個名詞,也就是Transform。
看不到就剔除
PolyMorph Engine運算完畢後,數據接著由Raster Engine處理。Raster Engine只有3個階段,分別是Edge Setup(邊緣建立)、Rasterizer(光柵器)和Z-Cull(Z座標剔除)。Raster Engine運作方式不難理解,首先在Edge Setup階段,頂點位置被取出,並處理三角形邊緣。最重要的是,在這個階段中,必須要將視角中看不到、不需要再視角顯示的頂點與三角形剔除。
例如在大象背面有隻看不到的老鼠,雖然在3D空間中它是存在的,但是受到視角的限制,老鼠在2D螢幕中並不存在。因此可省略運算老鼠的模組,以提升運算效率。每個Edge Setup單元,能夠在1個周期內處理1個點、1條線,或是1個三角形。
接著在Rasterizer運作的過程中,會計算每個方程式的像素覆蓋率,如果開啟反鋸齒功能,則會在這個階段計算覆蓋率以進行反鋸齒採樣。最後在著色之前,Z-Cull會擷取Pixel Tile(像素磚),將已經運算完畢的Pixel Tile與處理中的Pixel Tile進行空間深度比對,將位於其他Pixel Tile背面的Pixel Tile刪除(也就是螢幕中不可見的部分),避免進入著色器浪費運算效能。
 (點圖可放大)
(點圖可放大)
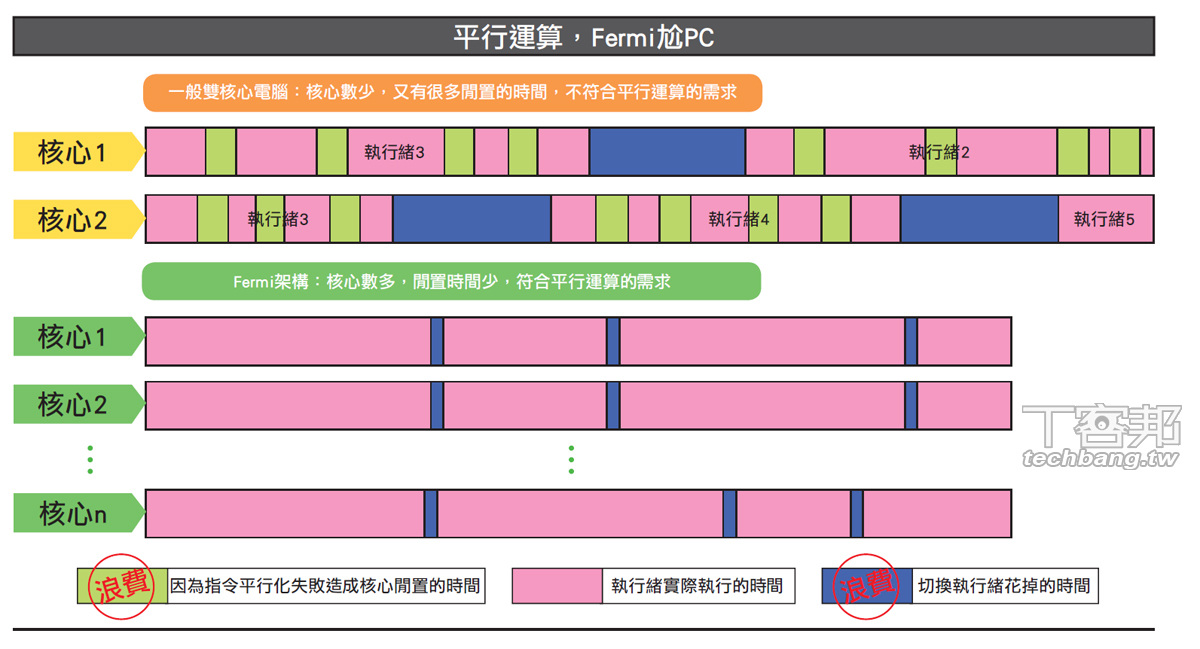
▲我們從當年Fermi的平行運算圖來看,大量核心配合Giga Thread快速轉換執行緒,運算效率高於一般多核心電腦。即使到了Kepler時期,這個方向與架構仍未有改變,而且透過部署更多的核心,運算效率可望向上提升。
Warp Scheduler
CUDA Core會接受來自Warp Scheduler的命令,以便執行某個執行緒(Thread)。在SMX中,共有4組Warp Scheduler與192個CUDA Core,一次最多可執行192個執行緒,而這192個被挑到的執行緒就叫做Warp。
而Warp Scheduler的作用顧名思義就是進行Warp排程,能按照每個Warp可能佔用的資源進行排程並最佳化,避免造成核心資源的閒置或阻塞。舉例來說,SMX內有32個SFU,此時有個執行緒需要使用SFU進行運算,為了避免阻塞所以它不會被排入下一道指令,Warp Scheduler會先行處理順位較後面,且不需要透過SFU運算的執行緒。
Giga Thread Engine
先前在Fermi時代,最多可同時執行512個執行緒,到了Kepler時代,因為CUDA Core數量增加,同時間最多會有1536個執行緒。這個數量聽起來說多不多,說少也不少,但是處理排程不會這麼簡單,即便是Fermi核心只需處理512個執行緒,但是在平行運算時,使用者可能預先開了上百萬個執行緒在等待,例如在跑Folding@home。
▲Raster Engine所要處理的就是這3個階段,用比較簡單的話來說明,就是把3D變2D,然後把被遮蔽的物件剔除,以減少資源的消耗。
GPU內的核心幾乎永遠都有新的工作,而不會閒置,但是在執行緒與執行緒間是否能快速切換就是影響效能的關鍵,而這快速切換的關鍵就是Giga Thread Engine。GPU在平行運算方面的另一個優勢,就是執行緒間的切換較快。一般CPU切換執行緒約需數百微秒,但是在Giga Thread Engine運作下,GPU轉換執行緒只要25微秒,對於大量執行緒的切換而言,這點「小小」的時間差會造成明顯的效能差距。
Keywords:Displacement Mapping
這技術存在已久,但是到了DirectX 11才開始普及,原因在於Displacement Mapping需要大量的頂點才能發揮作用。例如上述的石板若只有10個頂點,自然無法形成理想的的峽谷。只有具備大量的頂點,才能夠成細緻的貼圖。以實務上來說,透過Tessllation生成的大量頂點,才能造出細緻的貼圖。
(後面還有:Kepler:4大軟硬體新技術)

1.一台主機要做2560*1600解析度(用WFP3008)
2.使用DVI-D輸出解析度到1920*1200都正常,到2560*1600字就像被狗啃得一下,換過線材,顯示卡都一樣
3.使用DISPLAY PORT沒有這個問題
4.但是我需要使用DVI PORT有解嗎?
求解法~
回覆可以回到我的EMAIL~
> 拜讀了大大的文章,小弟目前遇到一個問題
> 1.一台主機要做2560*1600解析度(用WFP3008)
> 2.使用DVI-D輸出解析度到1920*1200都正常,到2560*1600字就像被狗啃得一下,換過線材,顯示卡都一樣
> 3.使用DISPLAY PORT沒有這個問題
> 4.但是我需要使用DVI PORT有解嗎?
>
> 求解法~
> 回覆可以回到我的EMAIL~
先問一下,你用的線材是否支援Dual-link DVI,雖然都是dvi線材,但是要上高解析度必須用Dual-link DVI線材才行。從外觀來看,Dual-link DVI線材會比一般dvi線粗上一倍。
>
> 我們可以期待不久之後,可能會有更高階的GTX 685或是雙核心GTX 690。
GTX 690 早就已經出來了
不用再期待了,現在要買馬上就有
你只需要期待 GTX 685 而已