
ADVERTISEMENT
在訓練AI模型的過程中,往往需要輸入大量的訓練樣本資料,才能提升AI模型精確度,為了改善這個問題,NVIDIA提出ADA技術,能在維持同樣良好訓練成果的前提下,大幅縮減所需的樣本數量。
AI訓練仰賴大量資料
簡單的說,一般的AI運算可以分為2部分,首先需要在「AI訓練」階段透過輸入大量樣本,讓AI模型能夠知道它的工作任務是什麼。當AI模型訓練好之後,就可以在「AI推論」階段執行交付給它的工作。
舉例來說,如果我們想要透過AI來分辨照片中的動物是貓或狗的話,就需在AI訓練階段提供大量貓與狗的照片,讓AI模型學習其中的特徵,然後在AI推論階段就可以輸入全新的照片,讓AI模型去分辨這張照片中的主角是貓還是狗。
一般來說,如果在在AI訓練階段輸入越多樣本資料,訓練出來的模型精準度就越高。然而我們還是會遇到無法準備大量樣本的情況,比方想要透過AI分辨罕見疾病的X光、超音波、核磁共振等醫學影像,但卻因為累積的病例數太少,或是想要透過AI模仿某位畫家的風格,但他流傳的作品並不多,而無法提供充分的影像。

在樣本圖片上動手腳,憑空生出新樣本
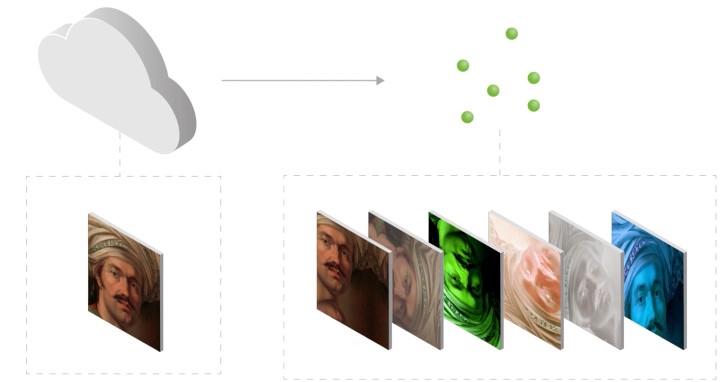
對於生成對抗網路(GAN)而言,如果只是使用少量的數千張影像進行訓練,可能會發生鑑別網路只是單純記住訓練影像,而無法提供有用的回饋給生成網路,產生過度擬合(Overfitting)的問題,降低產出影像的逼真感。
過去就有研究人員嘗試過把透過修改訓練影像來增加樣本的想法,但往往造成生成網路學習扭曲後的影像,最終無法產生可信度的合成影像。NVIDIA這次提出的ADA(Adaptive Discriminator Augmentation,自我調整判別器增強)技術則可避免此一問題,透過對原始圖片進行移動、旋轉、改變亮度、改變顏色等修改產生新的樣本,並送回對抗網路進行AI訓練,如此一來便能發揮在維持相同模型精確度的前提下,降低樣本需求量至原本的1/10甚至1/20。其最終好處就是僅需使用一般生成對抗網路所需學習材料的一小部分,就能學習到像是模仿著名畫家的畫風,以及重現癌症組織影像這般複雜的技能。
▲可以參考此影片中對於ADA與StyleGAN2的動態展示。
ADA雖然無法直接縮段AI訓練所需的時間,或是提升最終AI模型的精確度,但確可以有效降低訓練過程所需的樣本數量。有興去的讀者可以參考「Training Generative Adversarial Networks with Limited Data」論文,以瞭解更多資訊。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!