ADVERTISEMENT
身為目前最強的AI加速運算單元,Blackwell GPU不但具有強悍的效能,還可透過串接多組GPU方式構建「超大型GPU」,帶來更高的總體效能與吞吐量。
不同散熱與介面組態
NVIDIA推出了多種Blackwell GPU組態,包含整合8組GPU的HGX形式超級電腦,以及整合2組GPU搭配1組Grace CPU的GB200運算節點,而它們又可以彼此串連成為更大型的運算叢集。
- 延伸閱讀:
- GTC 24:Blackwell架構詳解(上),全新架構帶來5倍效能表現
- GTC 24:Blackwell架構詳解(下),看懂B100、B200、GB200、GB200 NVL72成員的糾結瓜葛(本文)
- GTC 2024春季場系列報導目錄
NVIDIA在GTC大會上主要推廣的型號為整合2組Blackwell GPU與1組Grace CPU的GB200 Superchip,NVIDIA推出的GB200 Superchip運算節點(Compute Node)則是將2組GB200 Superchip安置於1U高度的伺服器,並採用水冷散熱方案,能讓單組GB200 Superchip的TDP達到2700W,完全解放效能表現。
ADVERTISEMENT
此外NVIDIA也會推出採用SXG介面的B200與B100等GPU,且都能夠以8組GPU組成HGX B200或HGX B100伺服器,2者主要的差異在於B200的TDP最高可達1000W,而B100僅為800W。
NVIDIA超大規模與高效能運算副總裁暨總經理Ian Buck也在媒體訪談中補充說明,若將B200安置於伺服器並搭配水冷散熱方案,則可將TDP上調至1200W,進一步提高運算效能。
另一方面,在散熱與供電許可的範圍下,B200與B100 GPU能夠直接與現有H100 HGX或相容伺服器進行GPU替換(Drop-in Replace),提供更大的升級彈性並節省升級費用。
ADVERTISEMENT
(若下方表格無法完整顯示,請點選我看圖片版)
{kind=link}
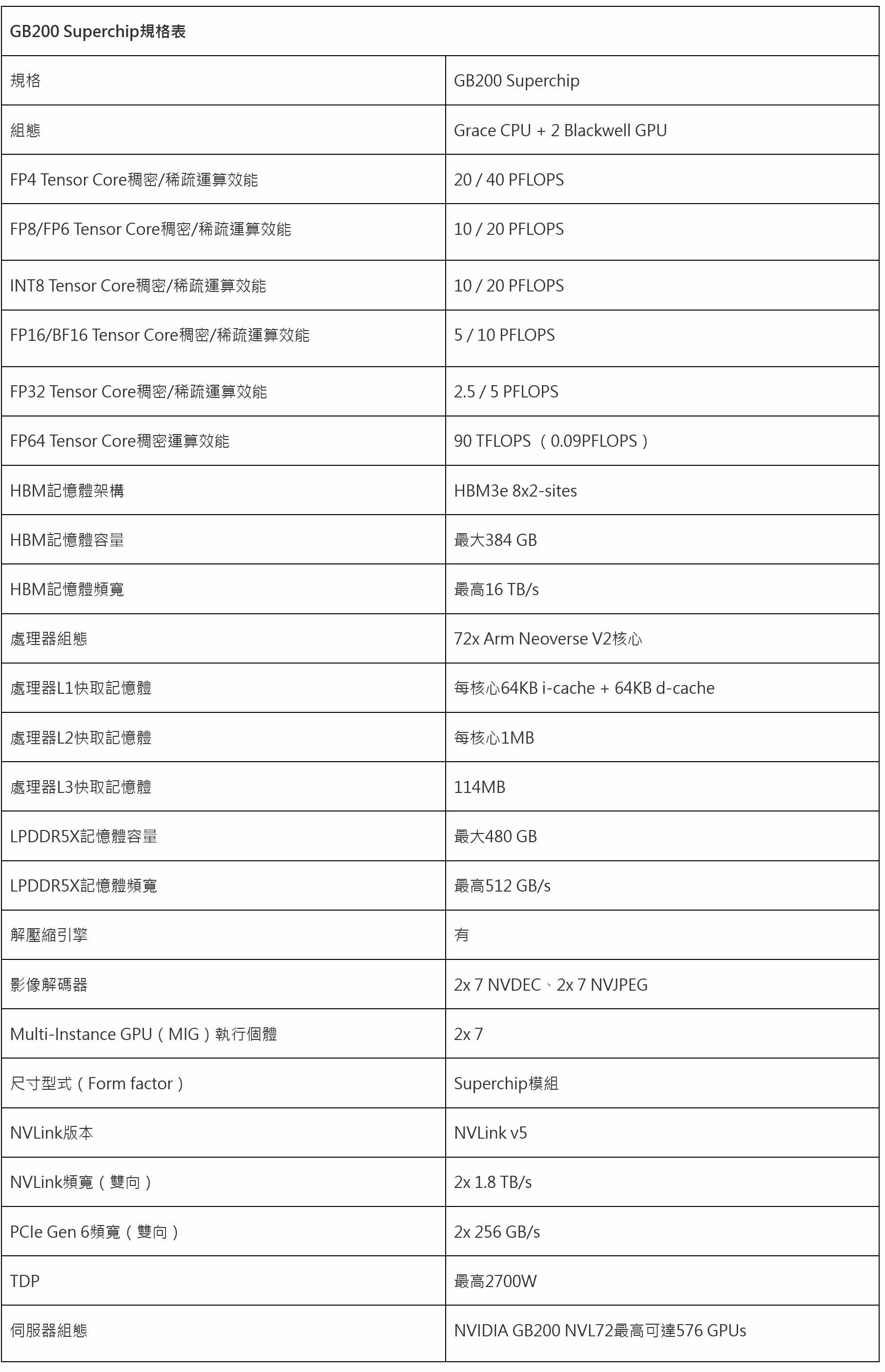
| GB200 Superchip規格表 | |
| 規格 | GB200 Superchip |
| 組態 | Grace CPU + 2 Blackwell GPU |
| FP4 Tensor Core稠密/稀疏運算效能 | 20 / 40 PFLOPS |
| FP8/FP6 Tensor Core稠密/稀疏運算效能 | 10 / 20 PFLOPS |
| INT8 Tensor Core稠密/稀疏運算效能 | 10 / 20 PFLOPS |
| FP16/BF16 Tensor Core稠密/稀疏運算效能 | 5 / 10 PFLOPS |
| FP32 Tensor Core稠密/稀疏運算效能 | 2.5 / 5 PFLOPS |
| FP64 Tensor Core稠密運算效能 | 90 TFLOPS (0.09PFLOPS) |
| HBM記憶體架構 | HBM3e 8x2-sites |
| HBM記憶體容量 | 最大384 GB |
| HBM記憶體頻寬 | 最高16 TB/s |
| 處理器組態 | 72x Arm Neoverse V2核心 |
| 處理器L1快取記憶體 | 每核心64KB i-cache + 64KB d-cache |
| 處理器L2快取記憶體 | 每核心1MB |
| 處理器L3快取記憶體 | 114MB |
| LPDDR5X記憶體容量 | 最大480 GB |
| LPDDR5X記憶體頻寬 | 最高512 GB/s |
| 解壓縮引擎 | 有 |
| 影像解碼器 | 2x 7 NVDEC、2x 7 NVJPEG |
| Multi-Instance GPU(MIG)執行個體 | 2x 7 |
| 尺寸型式(Form factor) | Superchip模組 |
| NVLink版本 | NVLink v5 |
| NVLink頻寬(雙向) | 2x 1.8 TB/s |
| PCIe Gen 6頻寬(雙向) | 2x 256 GB/s |
| TDP | 最高2700W |
| 伺服器組態 | NVIDIA GB200 NVL72最高可達576 GPUs |
(若下方表格無法完整顯示,請點選我看圖片版)
{kind=link}
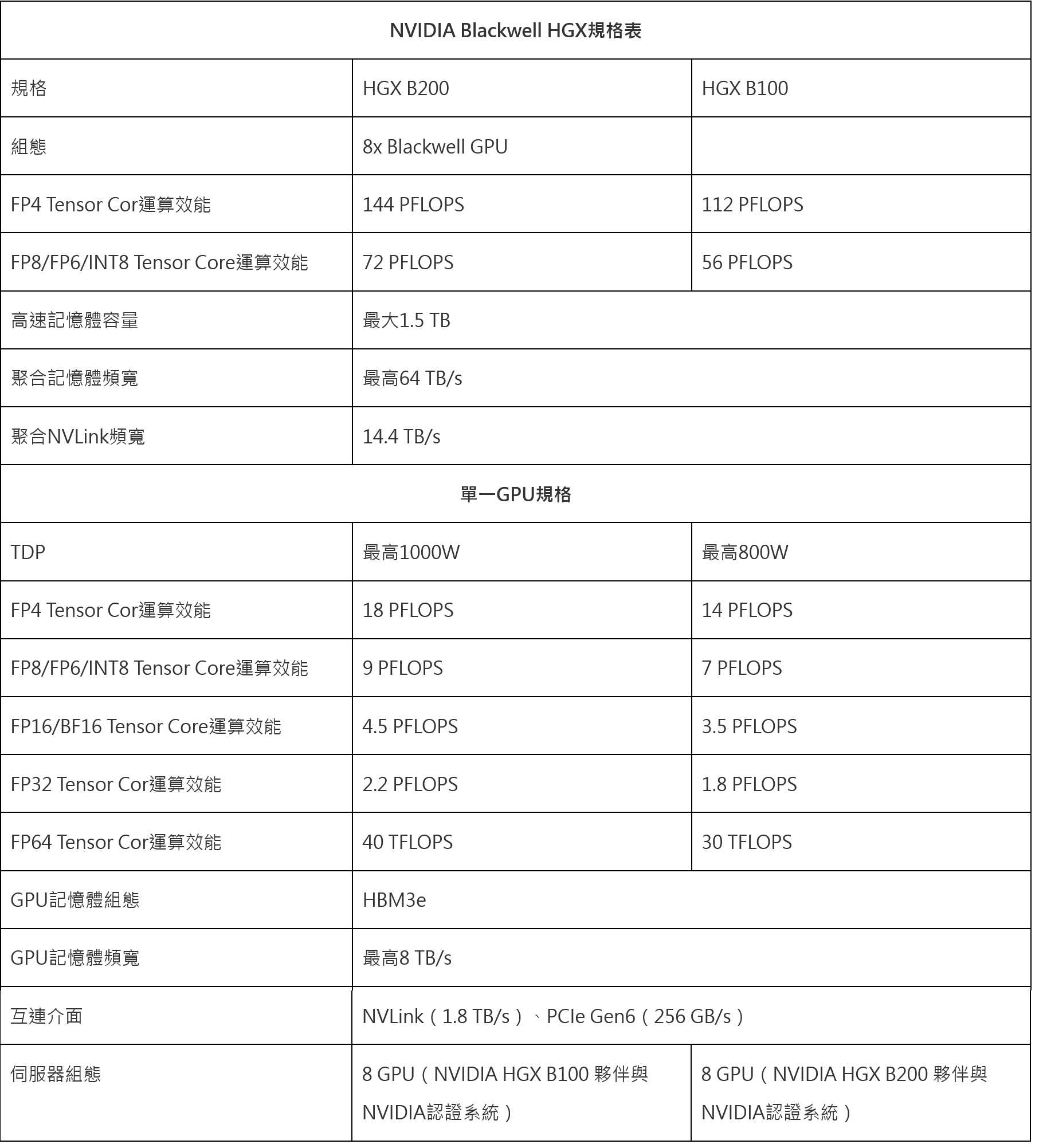
| NVIDIA Blackwell HGX規格表 | ||
| 規格 | HGX B200 | HGX B100 |
| 組態 | 8x Blackwell GPU | |
| FP4 Tensor Cor運算效能 | 144 PFLOPS | 112 PFLOPS |
| FP8/FP6/INT8 Tensor Core運算效能 | 72 PFLOPS | 56 PFLOPS |
| 高速記憶體容量 | 最大1.5 TB | |
| 聚合記憶體頻寬 | 最高64 TB/s | |
| 聚合NVLink頻寬 | 14.4 TB/s | |
| 單一GPU規格 | ||
| TDP | 最高1000W | 最高800W |
| FP4 Tensor Cor運算效能 | 18 PFLOPS | 14 PFLOPS |
| FP8/FP6/INT8 Tensor Core運算效能 | 9 PFLOPS | 7 PFLOPS |
| FP16/BF16 Tensor Core運算效能 | 4.5 PFLOPS | 3.5 PFLOPS |
| FP32 Tensor Cor運算效能 | 2.2 PFLOPS | 1.8 PFLOPS |
| FP64 Tensor Cor運算效能 | 40 TFLOPS | 30 TFLOPS |
| GPU記憶體組態 | HBM3e | |
| GPU記憶體頻寬 | 最高8 TB/s | |
| 互連介面 | NVLink(1.8 TB/s)、PCIe Gen6(256 GB/s) | |
| 伺服器組態 | 8 GPU(NVIDIA HGX B100 夥伴與 NVIDIA認證系統) |
8 GPU(NVIDIA HGX B200 夥伴與 NVIDIA認證系統) |
ADVERTISEMENT
ADVERTISEMENT
透過高速互連頻寬組成超大GPU
Blackwell GPU的另一大創新功能,就是能夠透過NVLink串聯最多576組Blackwell GPU,讓整個叢集猶如組成單一超大GPU,達到擴大運算效能、共享記憶體、執行規模更大模型的能力。
而NVIDIA也推出了GB200 NVL72伺服器,它的機櫃(Rack)具有18組GB200 Superchip運算節點以及9組NVLink交換器(每組交換器具有2組NVLink交換器晶片所),能在由72組GPU組成的NVL72網域叢集中,以130 TB/s的頻寬交換資料。而跨多台機櫃的GPU資料則會透過InfiniBand網路傳輸。
相對於Blackwell GPU晶片內部的2組裸晶透過頻寬高達10 TB/s的NV-HBI(NVIDIA High-Bandwidth Interface)晶片對晶片互連(Chip-to-Chip Interconnection)相連,多顆GPU之間則是透過第5代NVLink相連。它採用18通道(Link)的高速差分訊號對(High-Speed Differential Pair),能夠提供總共高達1.8 TB/s的雙向頻寬(即單向為900 GB/s),最高能支援576組GPU相連,遠高於前代的256組GPU。
第5代NVLink的頻遠遠高出PCIe Gen 5x16的14倍,其1小時的雙向傳輸量總合約為6.32 PB,大約等同於18年4K電影串流的資料量,或是11組Blackwell GPU之間的傳數量總合就與整個網際網路相當,對於執行大型AI模型的效能表現扮演重要角色。
(若下方表格無法完整顯示,請點選我看圖片版)
{kind=link}
| NVIDIA GB200 NVL72規格表 | |
| 規格 | NVIDIA GB200 NVL72 |
| 組態 | 36x GB200 Superchip |
| FP4 Tensor Core稠密/稀疏運算效能 | 720 / 1440 PFLOPS |
| FP8/FP6 Tensor Core稠密/稀疏運算效能 | 360 / 720 PFLOPS |
| INT8 Tensor Core稠密/稀疏運算效能 | 360 / 720 PFLOPS |
| HBM記憶體架構 | HBM3e |
| HBM記憶體容量 | 最大13.5 TB |
| HBM記憶體頻寬 | 最高576 TB/s |
| 處理器組態 | 2592x Arm Neoverse V2核心 |
| 高速記憶體容量 | 最大30 TB |
| NVLink交換器 | 7x |
| NVLink頻寬(雙向) | 130 TB/s |
NVIDIA不但透過CUDA確立了AI運算軟體與框架的領先優勢,隨著Blackwell架構推出的第5代NVLink也支援串聯更多GPU,進而提供更龐大的運算能力以及記憶體總容量,讓競爭對手望塵莫及。
ADVERTISEMENT