
ADVERTISEMENT
最近,「Metaverse」的概念火了。
祖克伯帶著VR設備在虛擬辦公室接受採訪的影片在各大平臺傳播,人們似乎在期待一個新的時代的到來,就連相關的股票都應聲上漲。
那麼,我們離《一級玩家》中「綠洲」那樣的Metaverse還有多遠呢?
事實上,羅馬不是一下子建成的。祖克伯給「Metaverse」的計畫時間是五年,技術也需要一步一步落實,這其中包括很多正在快速發展的技術,比如全自由互動。
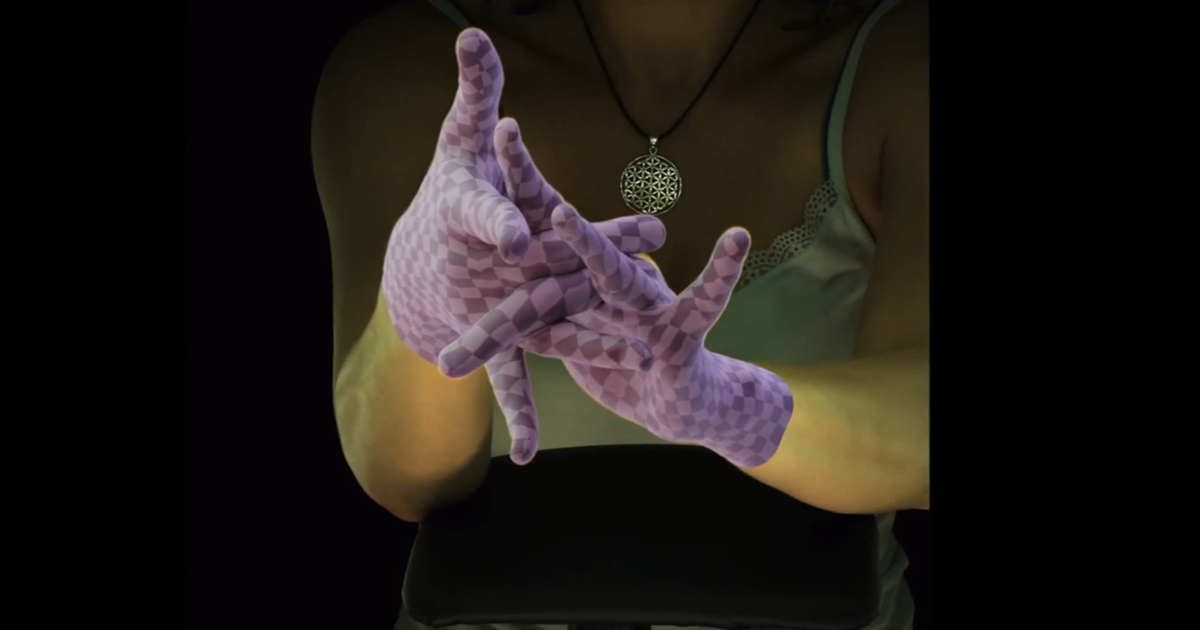
打個比方,如果我們要用我們的雙手和虛擬世界互動,那麼我們就需要對整個手部進行建模,像是這樣:

是不是覺得不過如此?確實,很早之前,我們通過佩戴指環就可以大體實現這樣的功能,但是,上面這張圖中所展現的效果,並未借助任何手指感測器,僅僅是透過AI演算法對攝影鏡頭中的手指進行建模就能得到如此精細的手部動作。
還覺得不過癮的話,看看這個對搓手動作的還原,簡直絲毫不差!
這項研究由來自愛丁堡大學的He Zhang和Facebook Reality Labs的幾位合作者共同完成,對,就是那個致力於更精確的VR技術的Facebook Reality Labs!
無需手指感測器,還原最真實的手指運動
與其他類似研究相比,這項研究幾乎擁有目前效果最好的手指動作建模。
這時候你可能覺得,這個AI還原的演算法是不是透過在手指上接上感測器,然後獲得大量的資料學習得來的?我們不妨看看論文附帶的示範影片:
注意看右上角的Input,手指上沒有任何感測器。
這一切都是依靠團隊提出的ManipNet深度神經網路演算法。ManipNet利用手-物體物件的空間之間的關係表徵,直接從資料中學習手部的自然動作。
論文中,作者表示,該空間表徵演算法結合了作為體素占比(3D空間分割上的最小單位)的整體物體形狀和作為最近距離樣本的物體局部的幾何細節。這種演算法使得深度神經網路可以透過從手腕和物體的輸入軌跡中模擬手指運動。
具體來說,ManipNet提供了過去、現在、未來三個節點的手指運動軌跡,以及從這些軌跡中提取的空間表徵,然後深度神經網路會根據這些已有的資料產生一個自回歸模型,預測從過去、現在到未來這幾個節點之間缺少的其他手指姿態。
如上圖所示,ManipNet是從控制訊號和物體幾何表徵中預測操縱物件的手指姿態((a)右手握住茶壺,左手握住杯子(b)右手轉動手中的圓環),其中控制訊號是手腕和物體的6D軌跡,並且該深度神經網路只需要一個最小的和明確的輸入表示,以便實現更好的泛化。
此外,ManipNet只處理一個手-物體的「輸入」,然後透過鏡像運算兩次,為雙手產生預測圖像。
FRL為「Metaverse」提供更好的VR技術
Facebook Reality Labs可以說是祖克伯實現「Metaverse」夢想的重要技術動力來源。
在官網介紹中,Facebook Reality Labs表示,這裡彙集了世界級的研究人員、開發人員和工程師團隊,在虛擬實境和增強現實中建立未來的連接。
就像ManipNet這樣的研究,正在不斷的為「Metaverse」中現實與虛擬的互動加入新的力量。
ManipNet的團隊研究人員也表示,手指互動在遊戲和AR/VR即時互動應用中有很大的潛力。「隨著AR/VR硬體在消費者市場的崛起,將我們的系統與其內置物件追蹤相結合可以為新的互動內容打開了許多創造性的機會。」
事實上,中國的一些公司也在研究相關技術,比如愛奇藝被電腦視覺領域國際頂會 ICCV 2021收錄的一篇題為「I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling」,介紹的也是透過「看」RGB人手圖片,就能實現高精度的人手3D重建。
愛奇藝這篇論文中提出的I2UV-HandNet,將UV映射表徵引入到3D手勢和形狀估計中,其設計的UV重建模組AffineNet能夠從單目圖像中預測手部網路(hand mesh),從而完成由粗到精的人手3D模型重建。
這一設計意味著對於3D重建中所需的空間中的景深資訊,不用再通過昂貴的硬體完成偵測,在普通RGB攝影鏡頭拍攝的圖片中就可以完成景深資訊獲取。
I2UV-HandNet另一個組成部分是SRNet網路,其作用是對已有人手3D模型進行更高精度的重建。SRNet網路以研究團隊獨創的「將點的超解析度成像轉化為圖像超解析度成像的想法」為原則,實現在不增加過多運算量的情況下,進行上萬點雲端的超解析度成像重建。
同樣,愛奇藝團隊也認為,手部、人體重建卻是用自然的肢體語言實現人機互動的關鍵技術,相比一些可穿戴設備,更能帶來體驗和沉浸度。例如手柄無法模擬手指每一個關節的活動,手部重建則能實現更加精細的操控。這意味著這項技術可以應用在遊戲、數位化工廠、虛擬場景培訓等更多場景。
相關報導:
- https://www.youtube.com/watch?v=_9Bli4zCzZY&ab_channel=TwoMinutePapers
- https://mp.weixin.qq.com/s/iyQRA6t4Ngcb7hRBdJ-ftw
- https://research.fb.com/wp-content/uploads/2021/06/ManipNet-Neural-Manipulation-Synthesis-with-a-Hand-Object-Spatial-Representation.pdf
- http://www.diankeji.com/vr/47299.html

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!