
ADVERTISEMENT
NVIDIA研究團隊於CVPR大會發表Vid2Vid Cameo相關論文(PDF),只需1張圖片就能輕易地打造數位虛擬化身、節省視訊頻寬,並能夠進行人臉辨識等強大功能,此外也推出可以簡化AI訓練流程的遷移學習工具套件3.0。
讓AI訓練更簡單
Vid2Vid Cameo是NVIDIA Maxine AI視訊串流平台背後、以生成對抗網絡(Generative Adversarial Network,GAN)為基礎的深度學習模型之一,使用者除了可以上傳自己的照片,也可以使用其他人的照片或卡通、漫畫頭像,並將這些靜態圖項轉換為即時反映使用者狀態的動態虛擬化身。
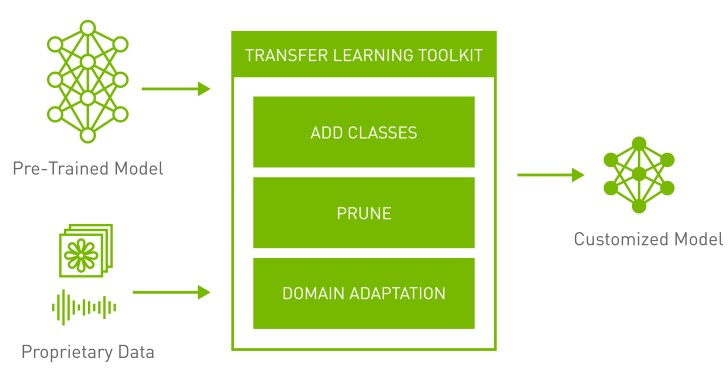
此外NVIDIA也發表Tao框架下的遷移學習工具套件3.0(Transfer Learning Toolkit 3.0),使用者可以透過NGC目錄免費取得預先訓練模型,有利於加速AI和電腦視覺(Computer vision)應用程式的部署,並輕鬆地將預先訓練的模型,搭配客製化調整資料,構築適用於特定情境的專屬AI模型。
▲從Vid2Vid Cameo的展示影片中可以看到角度校正、虛擬化身、節省頻寬等功能。


請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!