
Mozilla 其最大開源語音募集專案「同聲計畫(Common Voice)」, 日前已正式開始募集正體中文音檔,成為其語音資料的第一種亞洲語言;正體中文音檔目前在同聲計畫資料集中成長快速,已是英、法、德語以外的最大語音資料。
語音辨識已逐漸成為個人與電子裝置互動的首選方式,它能為使用者節省大量時間,同時技術發展也能跨越鍵盤、滑鼠或螢幕的框架。然而,今日的語音辨識技術大多掌握在少數透過既有產品優勢,以專屬平台收集語音的企業手中。
此外,現有商用數位及語音辨識服務往往也偏廢了弱勢語言。有鑑於此,Mozilla 認為需要建立多國語言開源語音資料庫,透過語音技術的民主化支持創新,也為視障者、未受教育者、兒童或年長者等相對的資訊弱勢族群降低取得資訊的門檻。

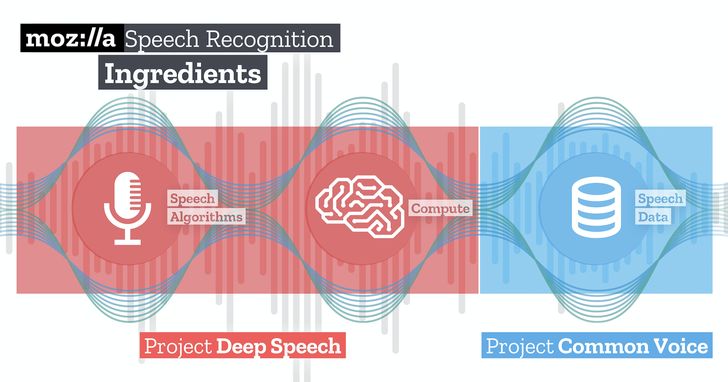
Mozilla 自去年七月開始啟動開源的同聲計畫,目標是收集用於訓練語音辨識技術的聲音數據,至今共有超過兩百位開發者參與計畫的軟體開發。到目前為止,同聲計畫已經募集了來自 112 個國家的兩萬四千多人所貢獻的聲音,收集到超過 900 小時的語音樣本,一躍成為全球第二大開源語音資料集。同聲計畫於上月開始收集多國音檔之後,預期在年底前可望成為全球最大開源語音資料集。
目前專案平台已擁有 60 種語言版本,並已開始收集 15 種語言音檔。Mozilla 繼上個月開始募集德、法語和威爾斯語錄音檔之後,日前也開始由正體中文著手,展開中文語音的音檔募集。
過去一年內,同聲計畫成長快速。Mozilla 於去年 11 月發表了同聲計畫第一版資料集,語音資料下載量至今已達數千次。同時也與 Mycroft、Snips.AI 以及威爾斯的 Bangor 大學等新創企業或校園夥伴進行語音收集與技術合作,所收集的語音資料同時也應用在 Mozilla 本身的語音辨識引擎「 深度語音辨識(Project DeepSpeech)」上。
Mozilla 目前正試圖打造全球最大的開源多語語音資料庫,歡迎所有中文使用者一起捐出聲音,協助強化中文語音資料庫,也可以透過 iOS 應用來捐獻語音錄音檔。

現在連口音也要強調自己是正統了?
╮(╯_╰)╭
我聽不懂您的「正體中文」,因為筆劃太多了。
╮(╯_╰)╭