
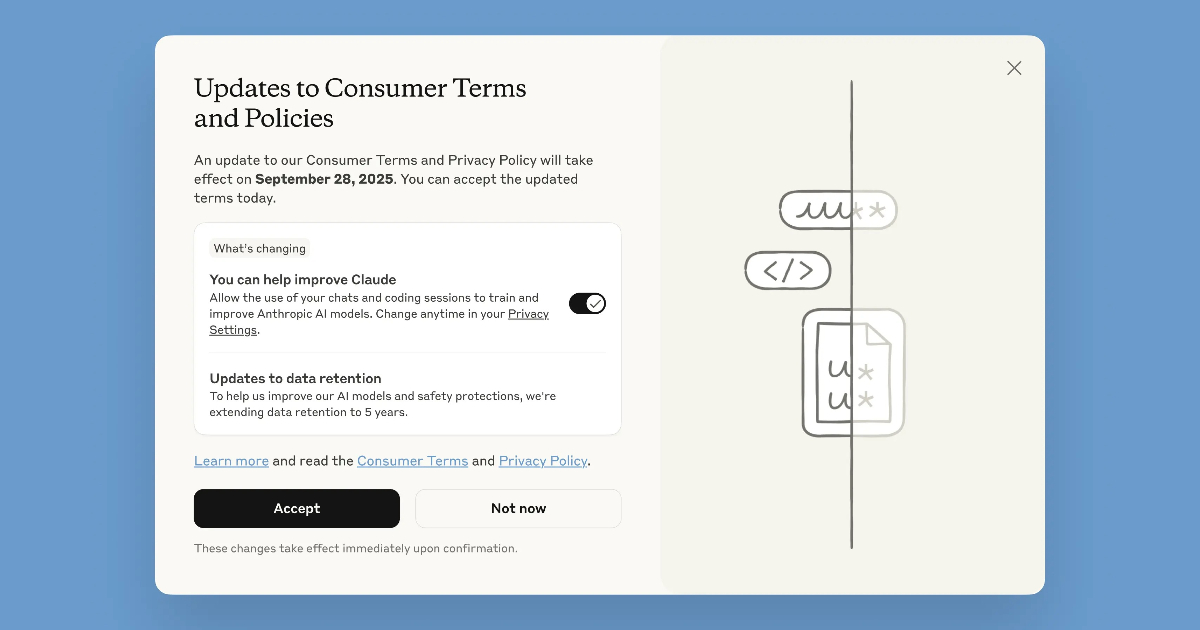
Anthropic 宣布正在更新消費者條款與隱私政策,未來將允許使用者選擇是否將聊天內容與程式開發工作階段的資料,用於訓練旗下大型語言模型 Claude。公司表示,此舉能幫助改進 Claude 的能力,包括程式設計、分析與推理,同時提升系統對詐騙與濫用等有害行為的防護能力。
用戶擁有完整選擇權
Anthropic 強調,用戶始終保有是否共享資料的決定權。
對於新用戶,在註冊時即可選擇是否同意使用聊天記錄來改進 Claude;現有用戶則會在近期看到彈出視窗通知,要求做出選擇。如果選擇立即同意,新政策會立刻生效,並且只影響新開啟或重新開啟的聊天與程式開發工作階段。過去已完成、且沒有再互動的對話內容,則不會被納入模型訓練。
若用戶當下不想決定,可以在彈窗中點選「稍後再說(not now)」,並在 2025 年 9 月 28 日之前完成設定。逾期未選擇者將無法繼續使用 Claude,直到做出決定為止。未來,用戶也能隨時透過「設定 → 隱私」頁面調整偏好。

聊天記錄會被保存多久?
新的政策將資料保存期限與是否參與訓練掛鉤:
-
若用戶允許資料用於模型訓練,新或續開的聊天與程式開發工作階段將被保存長達五年,以便支持模型開發與安全改進。
-
如果選擇不共享資料,則繼續維持 30 天的保存政策。
此外,用戶針對 Claude 回覆提交的意見回饋(feedback),同樣會在同意的情況下被保存五年。
值得注意的是,即便同意資料用於訓練,刪除聊天記錄後,該對話將不會再被納入未來的模型訓練。
不會影響所有服務
這次的更新只適用於 Claude Free、Pro、Max 用戶,包括使用 Claude Code 進行程式開發的情況。但如果使用的是以下服務,政策並不適用:
- Claude for Work(含 Team 與 Enterprise)
- Claude Gov
- Claude for Education
- 透過 API 存取 Claude,包括第三方平台,如 Amazon Bedrock 或 Google Cloud Vertex
換言之,如果企業或學校是透過商業方案或 API 服務使用 Claude,不會受到這次政策變更的影響。
Anthropic 如何保護隱私?
Anthropic 表示,公司會使用多種工具與自動化流程,盡可能過濾或模糊化敏感資訊,並強調「不會將用戶數據出售給第三方」。此外,若用戶日後改變心意,隨時可以在隱私設定中關閉資料共享功能。
需要注意的是,一旦資料已經被納入進行中的訓練或完成的模型,則無法從這些模型中移除,但 Anthropic 承諾會停止在未來的訓練中使用先前已儲存的聊天記錄。
為什麼需要更多資料?
Anthropic 解釋,訓練大型語言模型需要大量多樣化的資料,而來自實際互動的聊天記錄,能為模型提供真實的上下文與使用情境。例如,當開發者利用 Claude 偵錯程式碼時,這些過程中的數據有助於模型學習,進而在未來更準確地協助其他用戶完成相似任務。
公司同時指出,延長資料保存期限也能幫助提升安全性。長期資料能改進內部的濫用檢測系統,使其更有效識別詐騙、垃圾訊息與有害行為,進一步保障所有使用者的使用體驗。

請注意!留言要自負法律責任,相關案例層出不窮,請慎重發文!